Backend Guide¶
spark-bestfit uses a pluggable backend architecture that enables distribution fitting on different compute platforms. Choose the backend that matches your data location and infrastructure.
Note
Why “spark-bestfit” with multiple backends? The library was originally built
for Apache Spark, hence the name. v2.0 added pluggable backends while keeping the
name for backward compatibility—existing code using DistributionFitter(spark)
works unchanged. All backends use identical scipy fitting algorithms.
BackendFactory¶
The BackendFactory provides a centralized way to create backends:
from spark_bestfit.backends import BackendFactory
# Auto-detect from DataFrame type
backend = BackendFactory.for_dataframe(df)
# Explicit creation by name
backend = BackendFactory.create("spark", spark_session=spark)
backend = BackendFactory.create("ray")
backend = BackendFactory.create("local", max_workers=4)
# Check what's available
BackendFactory.get_available() # ["local", "spark", "ray"]
BackendFactory.is_available("spark") # True if pyspark installed
Auto-detection logic (for_dataframe):
Ray Dataset (duck typing: has
select_columnsandto_pandas) → RayBackendpandas DataFrame (isinstance check) → LocalBackend
Default (Spark DataFrame) → SparkBackend
Choosing a Backend¶
Backend |
Best For |
Data Input |
Install |
|---|---|---|---|
SparkBackend |
Production clusters, large datasets |
Spark DataFrame |
PySpark required (BYO or |
RayBackend |
Ray clusters, ML pipelines |
pandas DataFrame, Ray Dataset |
|
LocalBackend |
Testing, development, small data |
pandas DataFrame |
Included |
Decision Matrix¶
Scenario |
Recommended Backend |
Why |
|---|---|---|
Data in Spark DataFrames |
SparkBackend |
No data movement needed |
Data in pandas (< 10M rows) |
RayBackend or LocalBackend |
Lower overhead than Spark |
Data in Ray Datasets |
RayBackend |
Native distributed processing |
Unit tests |
LocalBackend |
No cluster dependencies |
100M+ rows |
SparkBackend |
Mature distributed histograms |
ML pipeline (Ray Tune/Train) |
RayBackend |
Same ecosystem |
SparkBackend¶
The default backend for production workloads with Spark clusters.
Installation: Included by default.
Usage:
from pyspark.sql import SparkSession
from spark_bestfit import DistributionFitter, SparkBackend
spark = SparkSession.builder.getOrCreate()
# Implicit (backward compatible)
fitter = DistributionFitter(spark)
# Explicit
backend = SparkBackend(spark)
fitter = DistributionFitter(backend=backend)
# Fit from Spark DataFrame
results = fitter.fit(df, column="value")
Configuration:
from pyspark.sql import SparkSession
spark = (
SparkSession.builder
.appName("DistributionFitting")
# Enable Arrow for efficient serialization
.config("spark.sql.execution.arrow.pyspark.enabled", "true")
# Enable Adaptive Query Execution
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
)
When to use:
Data already in Spark DataFrames
Existing Spark infrastructure (YARN, Kubernetes, Databricks)
Very large datasets (100M+ rows)
Need distributed histogram computation
RayBackend¶
Alternative backend for Ray clusters and ML pipelines.
Installation:
pip install spark-bestfit[ray]
Usage with pandas:
from spark_bestfit import DistributionFitter, RayBackend
import pandas as pd
import numpy as np
# Auto-initializes Ray if not running
backend = RayBackend()
fitter = DistributionFitter(backend=backend)
# Fit from pandas DataFrame
df = pd.DataFrame({"value": np.random.normal(50, 10, 10000)})
results = fitter.fit(df, column="value")
Usage with Ray Datasets:
import ray
# Create Ray Dataset
ds = ray.data.from_pandas(df)
# Distributed histogram computation
results = fitter.fit(ds, column="value")
When using Ray Datasets:
Histograms computed via distributed
map_batches()No raw data collected to driver
Automatic partitioning and parallelism
Cluster Connection:
# Auto-detect existing cluster
backend = RayBackend(address="auto")
# Connect to specific cluster
backend = RayBackend(address="ray://cluster-head:10001")
# Limit local resources
backend = RayBackend(num_cpus=8)
When to use:
ML pipelines (Ray Tune, Ray Train, Ray Serve)
Data in pandas or Ray Datasets
Kubernetes with Ray clusters
When Spark is unavailable
LocalBackend¶
Lightweight backend for testing and development. No cluster dependencies.
Installation: Included by default.
Usage:
from spark_bestfit import DistributionFitter, LocalBackend
import pandas as pd
backend = LocalBackend(max_workers=4)
fitter = DistributionFitter(backend=backend)
df = pd.DataFrame({"value": [1.0, 2.0, 3.0, 4.0, 5.0]})
results = fitter.fit(df, column="value")
When to use:
Unit tests (no Spark/Ray required)
Development and prototyping
Small datasets (< 100K rows)
CI/CD pipelines
Example test fixture:
import pytest
from spark_bestfit import DistributionFitter, LocalBackend
@pytest.fixture
def fitter():
return DistributionFitter(backend=LocalBackend())
def test_fit_normal(fitter):
df = pd.DataFrame({"x": np.random.normal(0, 1, 1000)})
results = fitter.fit(df, column="x")
assert results.best(n=1)[0].distribution == "norm"
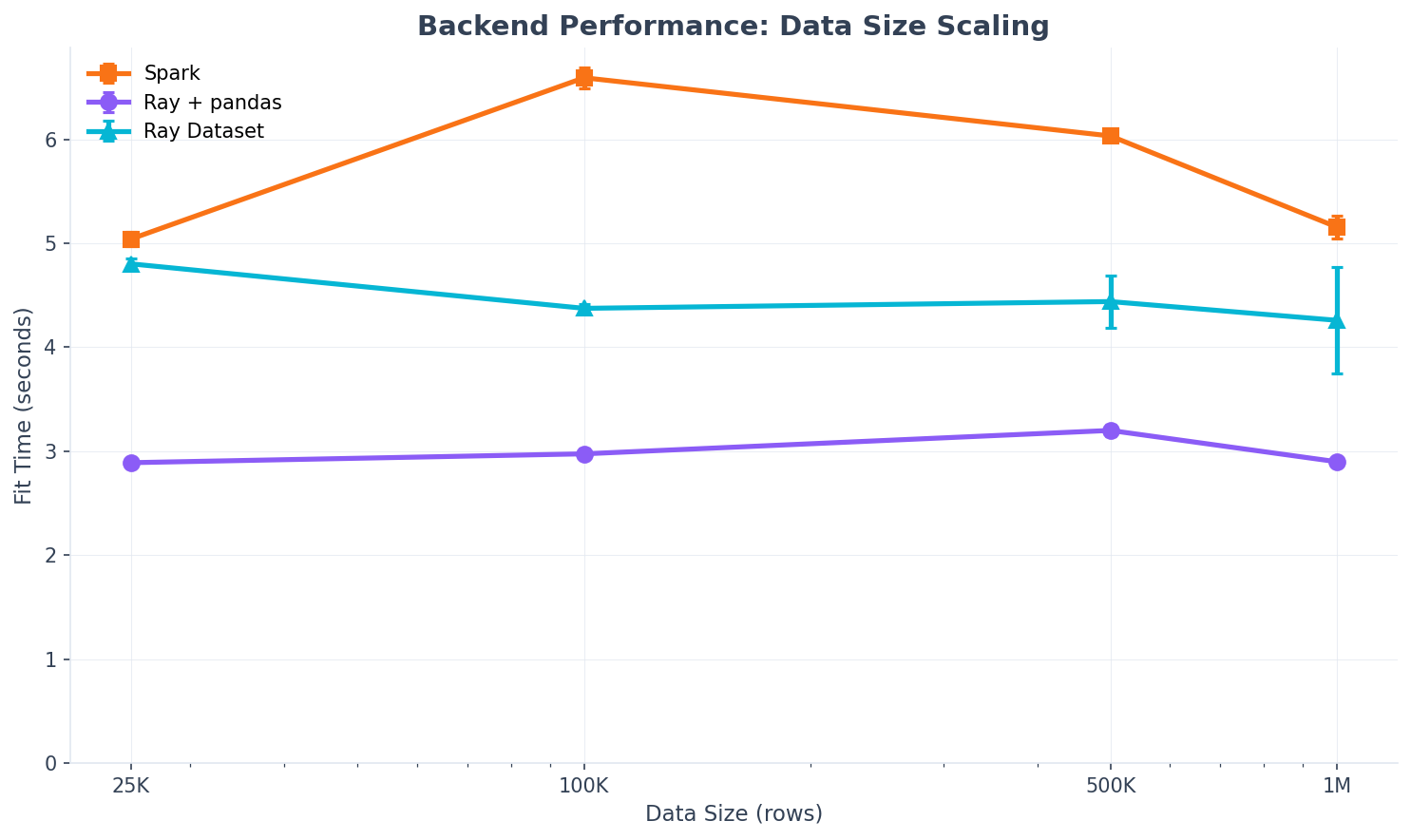
Performance Comparison¶
Benchmarks on local development machine (Apple M-series, 10 cores):
Data Size Scaling (90 distributions)
Data Size |
Spark |
Ray + pandas |
Ray Dataset |
Fastest |
|---|---|---|---|---|
25K |
4.8s |
2.8s |
4.8s |
Ray+pandas |
100K |
6.6s |
2.9s |
4.2s |
Ray+pandas |
1M |
5.0s |
2.7s |
4.5s |
Ray+pandas |
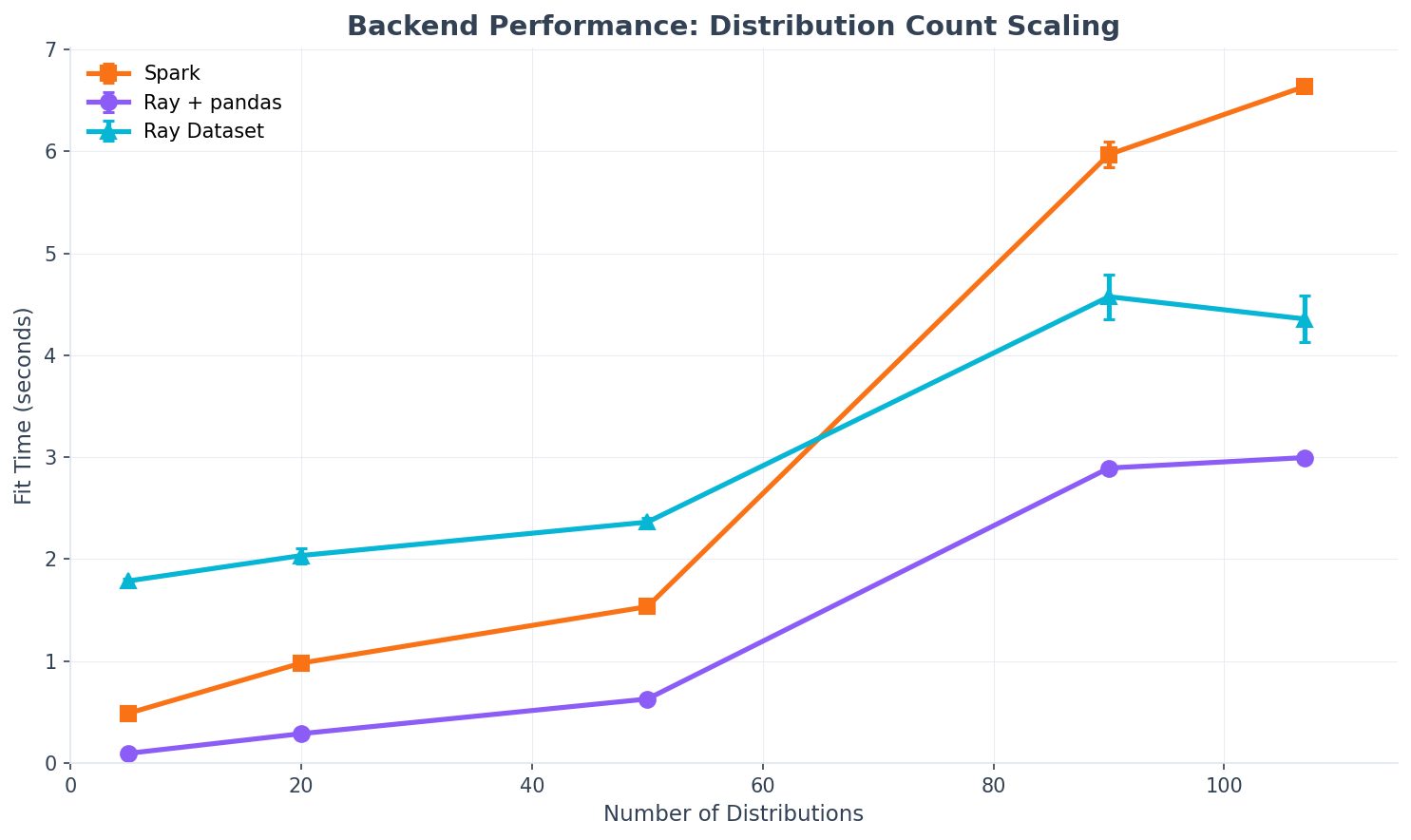
Distribution Count Scaling (10K rows)
Distributions |
Spark |
Ray + pandas |
Ray Dataset |
|---|---|---|---|
5 |
0.46s |
0.09s |
1.79s |
50 |
1.46s |
0.60s |
2.34s |
90 |
5.71s |
2.80s |
4.53s |
Key Observations:
Startup overhead: Spark has higher JVM startup cost; Ray+pandas is fastest for small workloads
Scaling: All backends show similar O(D) scaling with distribution count
Local mode: These benchmarks are local mode; cluster overhead is amortized on real clusters
Fit quality: All backends use identical scipy fitting - results are identical
Common Patterns¶
Backend-agnostic code:
from spark_bestfit import DistributionFitter
def fit_distribution(backend, data, column):
"""Works with any backend."""
fitter = DistributionFitter(backend=backend)
return fitter.fit(data, column=column)
# Use with Spark
results = fit_distribution(SparkBackend(spark), spark_df, "value")
# Use with Ray
results = fit_distribution(RayBackend(), pandas_df, "value")
# Use in tests
results = fit_distribution(LocalBackend(), test_df, "value")
Progress tracking (all backends):
from spark_bestfit.progress import console_progress
results = fitter.fit(
df,
column="value",
progress_callback=console_progress()
)
API Reference¶
- class spark_bestfit.backends.factory.BackendFactory[source]¶
Bases:
objectFactory for creating execution backends.
Provides centralized backend creation with: - Auto-detection from DataFrame type - Explicit string-based selection - Optional dependency handling
Example
>>> # Auto-detect from DataFrame >>> backend = BackendFactory.for_dataframe(df)
>>> # Explicit creation >>> backend = BackendFactory.create("local", max_workers=4)
>>> # Check availability >>> if BackendFactory.is_available("spark"): ... backend = BackendFactory.create("spark")
- classmethod create(backend_type: Literal['spark', 'local', 'ray'], **kwargs: Any) ExecutionBackend[source]¶
Create a specific backend by name.
- Parameters:
backend_type – One of “spark”, “local”, “ray”
**kwargs – Backend-specific arguments: - spark: spark_session (optional SparkSession) - local: max_workers (optional int) - ray: (no options currently)
- Returns:
Backend instance
- Raises:
ValueError – If backend_type is unknown
ImportError – If required dependencies not installed
- classmethod for_dataframe(df: Any) ExecutionBackend[source]¶
Auto-detect and create backend based on DataFrame type.
Detection order: 1. Ray Dataset (duck typing: has select_columns and to_pandas) 2. pandas DataFrame (isinstance check) 3. Spark DataFrame (default fallback)
- Parameters:
df – Input DataFrame (Spark, pandas, or Ray Dataset)
- Returns:
Appropriate backend instance
- Raises:
ImportError – If detected backend’s dependencies not installed
- class spark_bestfit.backends.spark.SparkBackend(spark: SparkSession | None = None)[source]¶
Bases:
objectApache Spark backend using Pandas UDFs for parallel distribution fitting.
This is the default backend for spark-bestfit. It uses Spark’s broadcast variables for efficient data sharing and Pandas UDFs for vectorized distribution fitting across the cluster.
- spark¶
The SparkSession instance used for distributed operations
- broadcast(data: Any) Any[source]¶
Broadcast data to all Spark executors.
Creates a read-only variable cached on each worker node. This is essential for sharing histogram and sample data efficiently without sending copies with each task.
- Parameters:
data – Data to broadcast (numpy arrays, tuples, etc.)
- Returns:
Spark Broadcast object wrapping the data
- static collect_column(df: DataFrame, column: str) ndarray[source]¶
Collect a single column from Spark DataFrame as numpy array.
Warning: This collects data to the driver node. Use sparingly for large datasets.
- Parameters:
df – Spark DataFrame
column – Column name to collect
- Returns:
Numpy array of column values
- static compute_correlation(df: DataFrame, columns: List[str], method: str = 'spearman') ndarray[source]¶
Compute correlation matrix using Spark ML.
Uses distributed computation via Spark ML’s Correlation, enabling correlation computation on DataFrames with billions of rows without collecting data to the driver.
- Parameters:
df – Spark DataFrame
columns – List of column names to compute correlation for
method – Correlation method (‘spearman’ or ‘pearson’)
- Returns:
Correlation matrix as numpy array of shape (n_columns, n_columns)
- static compute_histogram(df: DataFrame, column: str, bin_edges: ndarray) Tuple[ndarray, int][source]¶
Compute histogram using distributed Bucketizer and groupBy.
This is the key optimization: uses Spark ML’s Bucketizer to assign each row to a bin, then uses groupBy to count rows per bin. All computation happens in the cluster without collecting data.
- Parameters:
df – Spark DataFrame
column – Column to histogram
bin_edges – Array of bin edge values (n_bins + 1 values)
- Returns:
Tuple of (bin_counts, total_count) where bin_counts is an array of counts for each bin
- create_dataframe(data: List[Tuple[Any, ...]], columns: List[str]) DataFrame[source]¶
Create a Spark DataFrame from local data.
Used internally to create the distribution name DataFrame for parallel fitting.
- Parameters:
data – List of row tuples
columns – Column names
- Returns:
Spark DataFrame
- static destroy_broadcast(handle: Any) None[source]¶
Release broadcast variable from executor memory.
Uses unpersist() rather than destroy() because Spark’s lazy evaluation may still reference the broadcast in pending operations.
- Parameters:
handle – Broadcast variable returned by broadcast()
- generate_samples(n: int, generator_func: Callable[[int, int, int | None], Dict[str, ndarray]], column_names: List[str], num_partitions: int | None = None, random_seed: int | None = None) DataFrame[source]¶
Generate samples distributed across Spark partitions.
Uses mapInPandas to generate samples in each partition, enabling generation of millions of samples distributed across the cluster.
- Parameters:
n – Total number of samples to generate
generator_func – Function(n_samples, partition_id, seed) -> Dict[col, array] that generates samples for one partition
column_names – Names of columns in output
num_partitions – Number of partitions (None = default parallelism)
random_seed – Base random seed (partition_id added for uniqueness)
- Returns:
Spark DataFrame with generated samples
- static get_column_stats(df: DataFrame, column: str) Dict[str, float][source]¶
Compute min, max, and count for a column in a single pass.
Uses Spark aggregations to compute statistics efficiently without collecting all data to the driver.
- Parameters:
df – Spark DataFrame
column – Column name
- Returns:
‘min’, ‘max’, ‘count’. Values are NaN for empty DataFrames or columns with all null values, ensuring consistent return type with LocalBackend and RayBackend.
- Return type:
Dict with keys
- get_parallelism() int[source]¶
Get the default parallelism from Spark configuration.
Returns the total number of cores available across the cluster, which is used to determine optimal partition counts.
- Returns:
Number of available parallel execution slots
- parallel_fit(distributions: List[str], histogram: Tuple[ndarray, ndarray], data_sample: ndarray, fit_func: Callable[[...], Dict[str, Any]], column_name: str, data_stats: Dict[str, float] | None = None, num_partitions: int | None = None, lower_bound: float | None = None, upper_bound: float | None = None, lazy_metrics: bool = False, is_discrete: bool = False, progress_callback: Callable[[int, int, float], None] | None = None, custom_distributions: Dict[str, Any] | None = None, estimation_method: str = 'mle', censoring_indicator: ndarray | None = None) List[Dict[str, Any]][source]¶
Execute distribution fitting in parallel using Pandas UDFs.
This method encapsulates all Spark-specific operations for fitting: 1. Broadcasts histogram and sample data to executors 2. Creates a DataFrame of distribution names 3. Applies the fitting UDF to compute results in parallel 4. Collects and returns results
- Parameters:
distributions – List of scipy distribution names to fit
histogram – Tuple of (y_hist, bin_edges) for continuous or (x_values, pmf) for discrete distributions
data_sample – Sample data array for MLE fitting
fit_func – Pure Python fitting function (not used directly here; we use the Pandas UDF factories instead)
column_name – Name of the source column
data_stats – Optional dict with data_min, data_max, etc.
num_partitions – Number of partitions (None = auto)
lower_bound – Lower bound for truncated fitting
upper_bound – Upper bound for truncated fitting
lazy_metrics – If True, skip expensive KS/AD computation
is_discrete – If True, use discrete distribution fitting
progress_callback – Optional callback for progress updates. Called with (completed_tasks, total_tasks, percent) at the Spark task level via StatusTracker polling.
custom_distributions – Dict mapping custom distribution names to rv_continuous objects. These are broadcasted to executors for fitting custom distributions. (v2.4.0)
estimation_method – Parameter estimation method (v2.5.0): - “mle”: Maximum Likelihood Estimation (default) - “mse”: Maximum Spacing Estimation (robust for heavy-tailed data)
censoring_indicator – Boolean array where True=observed event, False=censored. When provided, uses censored MLE. (v2.9.0)
- Returns:
List of fit result dicts
- static sample_column(df: DataFrame, column: str, fraction: float, seed: int) ndarray[source]¶
Sample a column and collect as numpy array.
Performs distributed sampling before collection, reducing the amount of data transferred to the driver.
- Parameters:
df – Spark DataFrame
column – Column name
fraction – Fraction to sample (0 < fraction <= 1)
seed – Random seed for reproducibility
- Returns:
Numpy array of sampled values
- class spark_bestfit.backends.ray.RayBackend(address: str | None = None, num_cpus: int | None = None)[source]¶
Bases:
objectRay backend using @ray.remote for parallel distribution fitting.
This backend runs distribution fitting using Ray’s task-based parallelism. It supports both Ray Datasets (for big data operations) and pandas DataFrames.
- num_cpus¶
Number of CPUs available for parallel execution
- broadcast(data: Any) Any[source]¶
Put data in Ray’s object store for sharing across tasks.
- Parameters:
data – Data to broadcast (typically numpy arrays or tuples)
- Returns:
Ray ObjectRef that can be passed to remote tasks
- collect_column(df: Any, column: str) ndarray[source]¶
Extract a column as numpy array.
Supports both Ray Datasets and pandas DataFrames.
- Parameters:
df – Ray Dataset or pandas DataFrame
column – Column name to extract
- Returns:
Numpy array of column values
- compute_correlation(df: Any, columns: List[str], method: str = 'spearman') ndarray[source]¶
Compute correlation matrix using distributed statistics.
Supports both Ray Datasets and pandas DataFrames. For Ray Datasets with Pearson correlation, uses distributed computation of sufficient statistics (sums, products) to compute correlation without collecting raw data. Spearman correlation requires ranking and thus collects data (like Spark ML’s approach).
- Parameters:
df – Ray Dataset or pandas DataFrame
columns – List of column names to compute correlation for
method – Correlation method (‘spearman’ or ‘pearson’)
- Returns:
Correlation matrix as numpy array of shape (n_columns, n_columns)
- compute_histogram(df: Any, column: str, bin_edges: ndarray) Tuple[ndarray, int][source]¶
Compute histogram bin counts using distributed aggregation.
Supports both Ray Datasets and pandas DataFrames. For Ray Datasets, uses map_batches to compute partial histograms in each partition, then aggregates results without collecting raw data.
- Parameters:
df – Ray Dataset or pandas DataFrame
column – Column to histogram
bin_edges – Array of bin edge values (n_bins + 1 values)
- Returns:
Tuple of (bin_counts, total_count)
- create_dataframe(data: List[Tuple[Any, ...]], columns: List[str]) DataFrame[source]¶
Create a pandas DataFrame from local data.
Returns pandas DataFrame (not Ray Dataset) since the distribution name list is small and doesn’t benefit from distribution.
- Parameters:
data – List of row tuples
columns – Column names
- Returns:
Pandas DataFrame
- destroy_broadcast(handle: Any) None[source]¶
No-op for Ray - uses automatic reference counting.
Ray automatically garbage collects objects from the object store when no references remain. No explicit cleanup needed.
- Parameters:
handle – ObjectRef (ignored - Ray handles cleanup automatically)
- generate_samples(n: int, generator_func: Callable[[int, int, int | None], Dict[str, ndarray]], column_names: List[str], num_partitions: int | None = None, random_seed: int | None = None) DataFrame[source]¶
Generate samples using Ray tasks.
Uses Ray remote tasks to generate samples in parallel across multiple partitions, then concatenates results.
- Parameters:
n – Total number of samples to generate
generator_func – Function(n_samples, partition_id, seed) -> Dict[col, array]
column_names – Names of columns in output
num_partitions – Number of partitions (None = use CPU count)
random_seed – Base random seed (partition_id added for uniqueness)
- Returns:
Pandas DataFrame with generated samples
- get_column_stats(df: Any, column: str) Dict[str, float][source]¶
Compute min, max, and count for a column.
Supports both Ray Datasets and pandas DataFrames. For Ray Datasets, uses distributed aggregation without collecting data.
- Parameters:
df – Ray Dataset or pandas DataFrame
column – Column name
- Returns:
‘min’, ‘max’, ‘count’
- Return type:
Dict with keys
- get_parallelism() int[source]¶
Get the number of available CPUs.
- Returns:
Number of CPUs available for parallel execution
- parallel_fit(distributions: List[str], histogram: Tuple[ndarray, ndarray], data_sample: ndarray, fit_func: Callable[[...], Dict[str, Any]], column_name: str, data_stats: Dict[str, float] | None = None, num_partitions: int | None = None, lower_bound: float | None = None, upper_bound: float | None = None, lazy_metrics: bool = False, is_discrete: bool = False, progress_callback: Callable[[int, int, float], None] | None = None, custom_distributions: Dict[str, Any] | None = None, estimation_method: str = 'mle', censoring_indicator: ndarray | None = None) List[Dict[str, Any]][source]¶
Execute distribution fitting in parallel using Ray tasks.
Uses @ray.remote tasks to fit distributions concurrently across the Ray cluster. Data is placed in the object store once and shared across all tasks efficiently.
- Parameters:
distributions – List of scipy distribution names to fit
histogram – Tuple of (y_hist, bin_edges) for continuous or (x_values, pmf) for discrete distributions
data_sample – Sample data array for MLE fitting
fit_func – Pure Python fitting function (unused - we call fitting directly)
column_name – Name of the source column
data_stats – Optional dict with data_min, data_max, etc.
num_partitions – Ignored (Ray handles task scheduling)
lower_bound – Lower bound for truncated fitting
upper_bound – Upper bound for truncated fitting
lazy_metrics – If True, skip expensive KS/AD computation
is_discrete – If True, use discrete distribution fitting
progress_callback – Optional callback for progress updates. Called with (completed, total, percent) after each distribution.
custom_distributions – Dict mapping custom distribution names to rv_continuous objects. (v2.4.0) Note: Currently not supported for RayBackend - use SparkBackend or LocalBackend for custom distributions.
estimation_method – Parameter estimation method (v2.5.0): - “mle”: Maximum Likelihood Estimation (default) - “mse”: Maximum Spacing Estimation (robust for heavy-tailed data)
censoring_indicator – Boolean array where True=observed event, False=censored. When provided, uses censored MLE. (v2.9.0)
- Returns:
List of fit result dicts (only successful fits, SSE < inf)
- sample_column(df: Any, column: str, fraction: float, seed: int) ndarray[source]¶
Sample a column and return as numpy array.
Supports both Ray Datasets and pandas DataFrames.
- Parameters:
df – Ray Dataset or pandas DataFrame
column – Column name
fraction – Fraction to sample (0 < fraction <= 1)
seed – Random seed for reproducibility
- Returns:
Numpy array of sampled values
- class spark_bestfit.backends.local.LocalBackend(max_workers: int | None = None)[source]¶
Bases:
objectLocal backend using ThreadPoolExecutor for parallel distribution fitting.
This backend runs distribution fitting locally using Python threads. It’s primarily useful for testing and development without requiring a Spark cluster.
- max_workers¶
Number of worker threads for parallel execution
- static broadcast(data: Any) Any[source]¶
No-op broadcast for local execution.
In local mode, data is already accessible to all threads, so we simply return the data as-is.
- Parameters:
data – Data to “broadcast”
- Returns:
The same data (no transformation needed)
- static collect_column(df: DataFrame, column: str) ndarray[source]¶
Extract a column from pandas DataFrame as numpy array.
- Parameters:
df – Pandas DataFrame
column – Column name to extract
- Returns:
Numpy array of column values
- static compute_correlation(df: DataFrame, columns: List[str], method: str = 'spearman') ndarray[source]¶
Compute correlation matrix using pandas.
- Parameters:
df – Pandas DataFrame
columns – List of column names to compute correlation for
method – Correlation method (‘spearman’ or ‘pearson’)
- Returns:
Correlation matrix as numpy array of shape (n_columns, n_columns)
- static compute_histogram(df: DataFrame, column: str, bin_edges: ndarray) Tuple[ndarray, int][source]¶
Compute histogram bin counts using numpy.
- Parameters:
df – Pandas DataFrame
column – Column to histogram
bin_edges – Array of bin edge values (n_bins + 1 values)
- Returns:
Tuple of (bin_counts, total_count) where bin_counts is an array of counts for each bin
- static create_dataframe(data: List[Tuple[Any, ...]], columns: List[str]) DataFrame[source]¶
Create a pandas DataFrame from local data.
- Parameters:
data – List of row tuples
columns – Column names
- Returns:
Pandas DataFrame
- destroy_broadcast(handle: Any) None[source]¶
No-op cleanup for local execution.
- Parameters:
handle – Data reference (ignored)
- generate_samples(n: int, generator_func: Callable[[int, int, int | None], Dict[str, ndarray]], column_names: List[str], num_partitions: int | None = None, random_seed: int | None = None) DataFrame[source]¶
Generate samples locally.
Unlike SparkBackend, this generates all samples in a single call since there’s no distributed cluster to leverage.
- Parameters:
n – Total number of samples to generate
generator_func – Function(n_samples, partition_id, seed) -> Dict[col, array] that generates samples for one partition
column_names – Names of columns in output (for interface compatibility)
num_partitions – Ignored (no partitioning in local mode)
random_seed – Random seed for reproducibility
- Returns:
Pandas DataFrame with generated samples
- static get_column_stats(df: DataFrame, column: str) Dict[str, float][source]¶
Compute min, max, and count for a column.
- Parameters:
df – Pandas DataFrame
column – Column name
- Returns:
‘min’, ‘max’, ‘count’
- Return type:
Dict with keys
- get_parallelism() int[source]¶
Get the number of worker threads.
- Returns:
Number of parallel execution slots (max_workers)
- parallel_fit(distributions: List[str], histogram: Tuple[ndarray, ndarray], data_sample: ndarray, fit_func: Callable[[...], Dict[str, Any]], column_name: str, data_stats: Dict[str, float] | None = None, num_partitions: int | None = None, lower_bound: float | None = None, upper_bound: float | None = None, lazy_metrics: bool = False, is_discrete: bool = False, progress_callback: Callable[[int, int, float], None] | None = None, custom_distributions: Dict[str, Any] | None = None, estimation_method: str = 'mle', censoring_indicator: ndarray | None = None) List[Dict[str, Any]][source]¶
Execute distribution fitting in parallel using threads.
Uses ThreadPoolExecutor to fit distributions concurrently. Each distribution is fitted independently using the provided fit_func.
- Parameters:
distributions – List of scipy distribution names to fit
histogram – Tuple of (y_hist, bin_edges) for continuous or (x_values, pmf) for discrete distributions
data_sample – Sample data array for MLE fitting
fit_func – Pure Python fitting function to apply. For continuous distributions, this is fit_single_distribution. For discrete, use fit_single_discrete_distribution.
column_name – Name of the source column
data_stats – Optional dict with data_min, data_max, etc.
num_partitions – Ignored (uses max_workers instead)
lower_bound – Lower bound for truncated fitting
upper_bound – Upper bound for truncated fitting
lazy_metrics – If True, skip expensive KS/AD computation
is_discrete – If True, use discrete distribution fitting
progress_callback – Optional callback for progress updates. Called with (completed, total, percent) after each distribution.
custom_distributions – Dict mapping custom distribution names to rv_continuous objects. (v2.4.0)
estimation_method – Parameter estimation method (v2.5.0): - “mle”: Maximum Likelihood Estimation (default) - “mse”: Maximum Spacing Estimation (robust for heavy-tailed data)
censoring_indicator – Boolean array where True=observed event, False=censored. When provided, uses censored MLE. (v2.9.0)
- Returns:
List of fit result dicts (only successful fits, SSE < inf)
- static sample_column(df: DataFrame, column: str, fraction: float, seed: int) ndarray[source]¶
Sample a column and return as numpy array.
Filters out NaN and infinite values before sampling to ensure clean data for distribution fitting.
- Parameters:
df – Pandas DataFrame
column – Column name
fraction – Fraction to sample (0 < fraction <= 1)
seed – Random seed for reproducibility
- Returns:
Numpy array of sampled values (NaN/inf filtered)